|
I am a researcher at Tencent Hunyuan, where my work centers on large multimodal models and foundation models for physical AI. I obtained my Ph.D. from the Department of Automation at Tsinghua University, advised by Prof. Jiwen Lu . In 2020, I received my B.Eng. from the Department of Electronic Engineering, Tsinghua University, along with a dual B.Admin. degree from the School of Economics and Management, Tsinghua University. I am broadly interested in computer vision and deep learning. My research focuses on vision-language models, physical AI foundation models, world models, 3D/4D generation, and 3D vision. |

|
|
|
|
* indicates equal contribution, # indicates project lead / corresponding author |
|
Ziyi Wang, Xumin Yu, Yongming Rao#, Yonggen Ling, Yunheng Li, Oran Wang, Mingqi Gao, Yuchen Zhou, Yves Liang, Zuyan Liu, Yani Zhang, Rui Huang, Xiaoran Xu, Bowen Yuan, Yifu Yuan, Xu Tan, He Zhang, Yufei Huang, Shenghao Zhang, Hongsheng Wu, Han Hu, Zhengyou Zhang Technical Report, 2026 [arXiv] [Code] [Model] Hy-Embodied-VLM-1.0 is an efficient Mixture-of-Experts embodied foundation model (~3B activated) that, guided by an action-centric capability taxonomy, achieves state-of-the-art physical-world understanding and reasoning across 38 embodied benchmarks. |
|
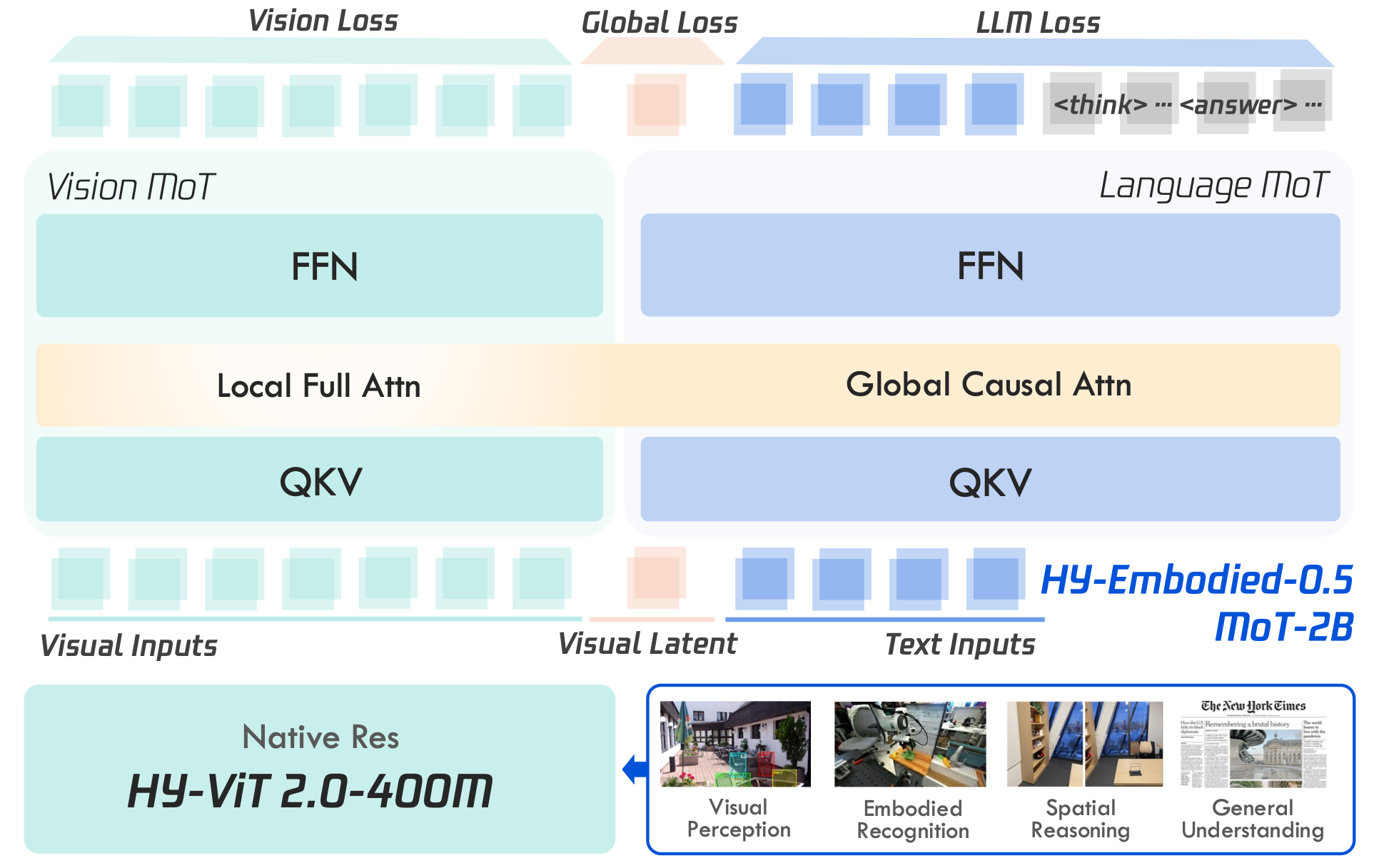
Xumin Yu*, Zuyan Liu*, Ziyi Wang*, He Zhang*, Yongming Rao#, Fangfu Liu, Yani Zhang, Ruowen Zhao, Oran Wang, Yves Liang, Haitao Lin, Minghui Wang, Yubo Dong, Kevin Cheng, Bolin Ni, Rui Huang, Han Hu, Zhengyou Zhang, Shunyu Yao Technical Report, 2026 [arXiv] [Code] [Model] HY-Embodied-0.5 is a family of embodied foundation models built for real-world agents, achieving state-of-the-art performance across 22 benchmarks in visual perception, spatial reasoning, and embodied understanding, with effective downstream robot control. |
|
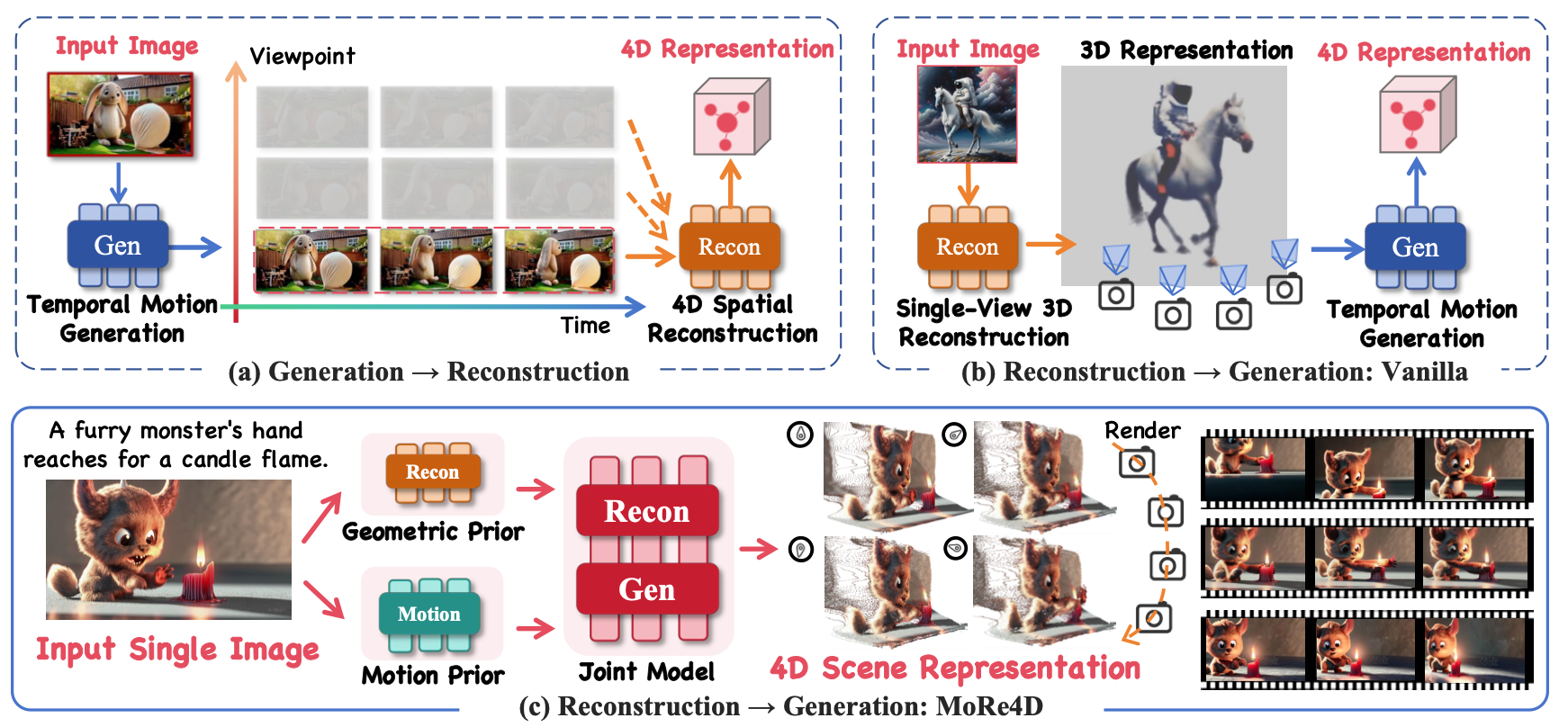
Yanran Zhang*, Ziyi Wang*, Wenzhao Zheng, Zheng Zhu, Jie Zhou , Jiwen Lu Preprint. [arXiv] [Code] MoRe4D synthesizes high-quality 4D scenes from a single image by jointly performing motion generation and 3D geometry reconstruction. |
|
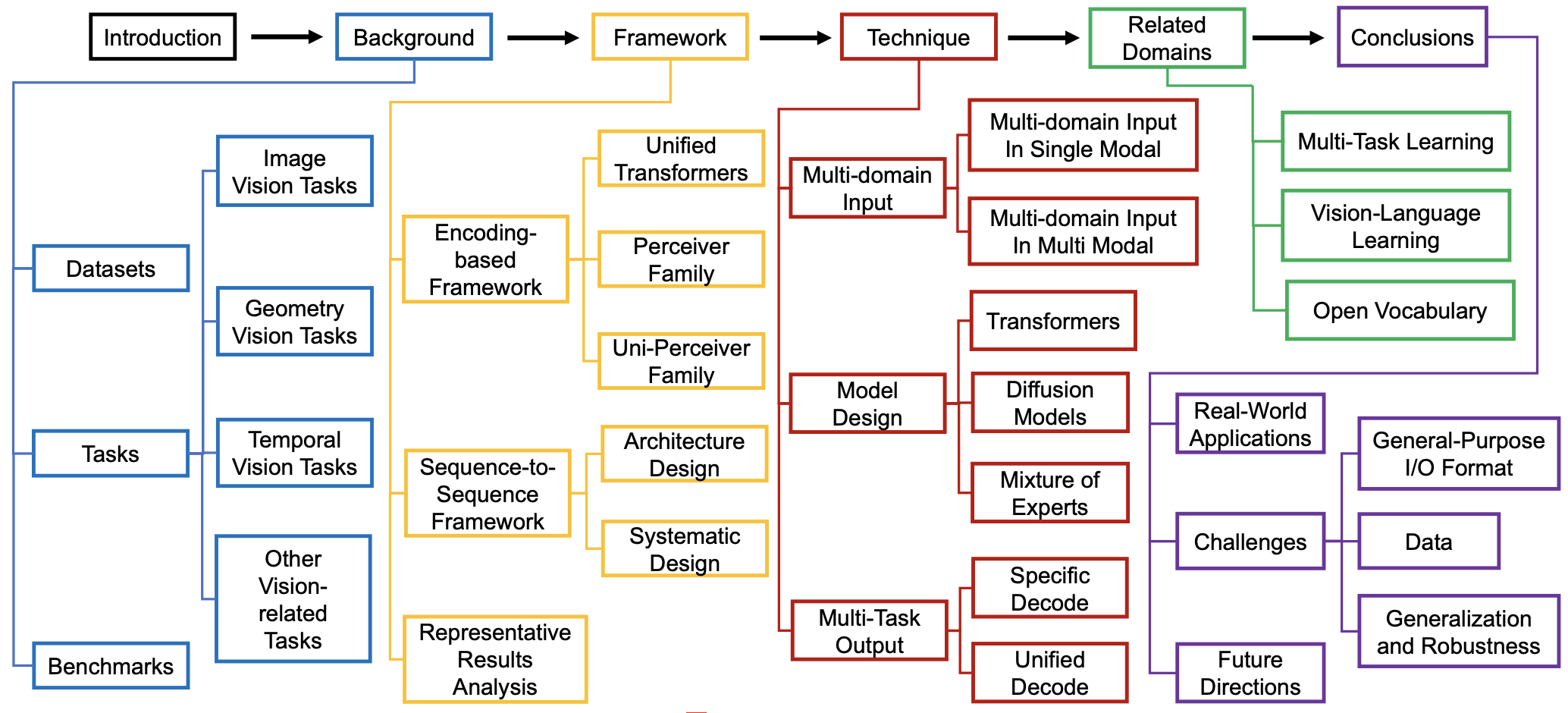
Ziyi Wang, Yongming Rao, Shuofeng Sun, Xinrun Liu, Yi Wei, Xumin Yu, Zuyan Liu, Yanbo Wang, Hongmin Liu, Jie Zhou , Jiwen Lu International Journal of Computer Vision (IJCV), 2025 [arXiv] We conduct a comprehensive survey on vision generalist models that support multimodal inputs and can handle various downstream tasks. |
|
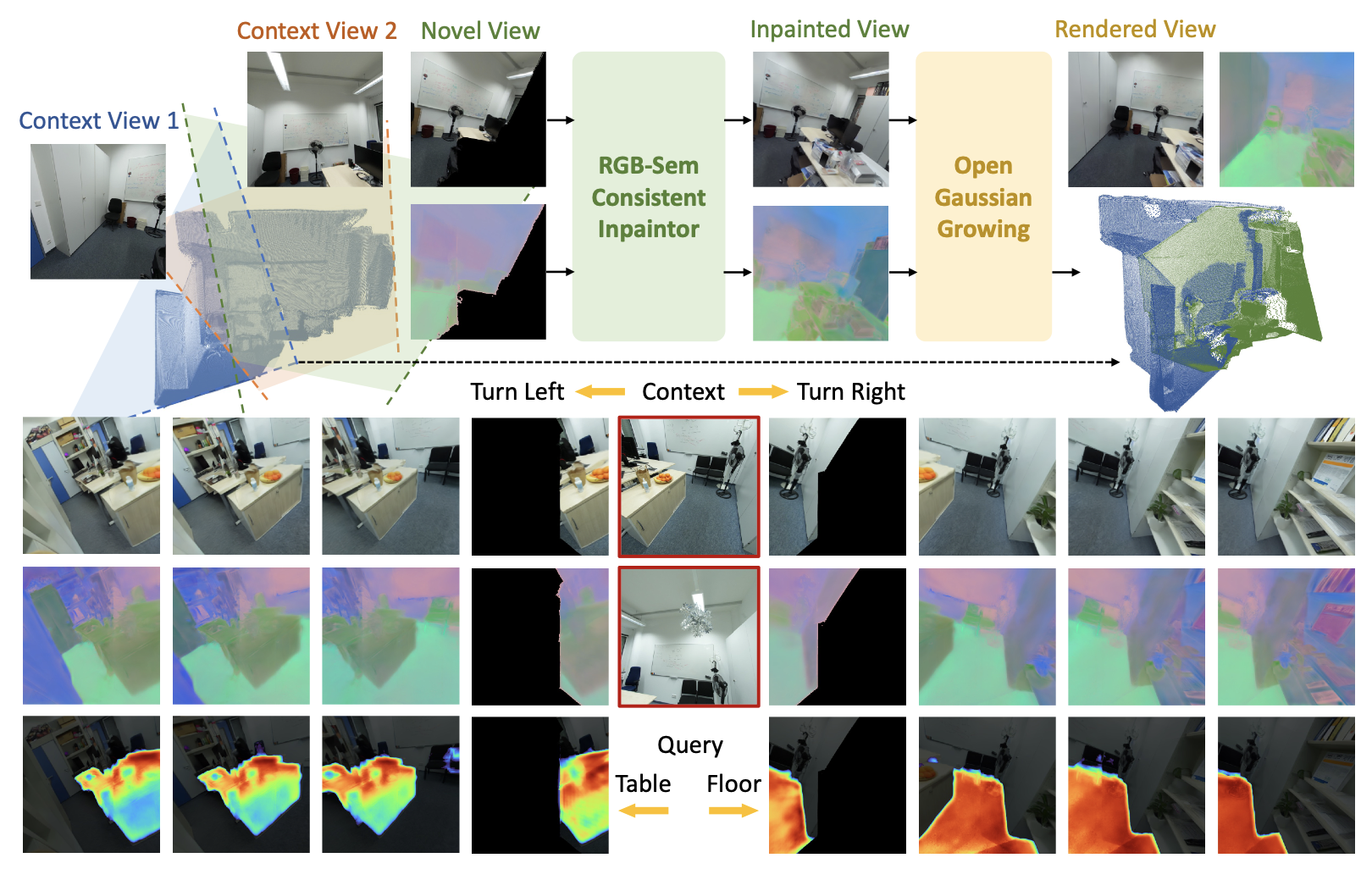
Yanbo Wang*, Ziyi Wang*, Wenzhao Zheng, Jie Zhou , Jiwen Lu Preprint. [arXiv] [Code] [Project Page] OGGSplat is designed to expand the field-of-view of the Gaussian-based 3D scene reconstructed from sparse views and feedforward / generalizable models. |
|
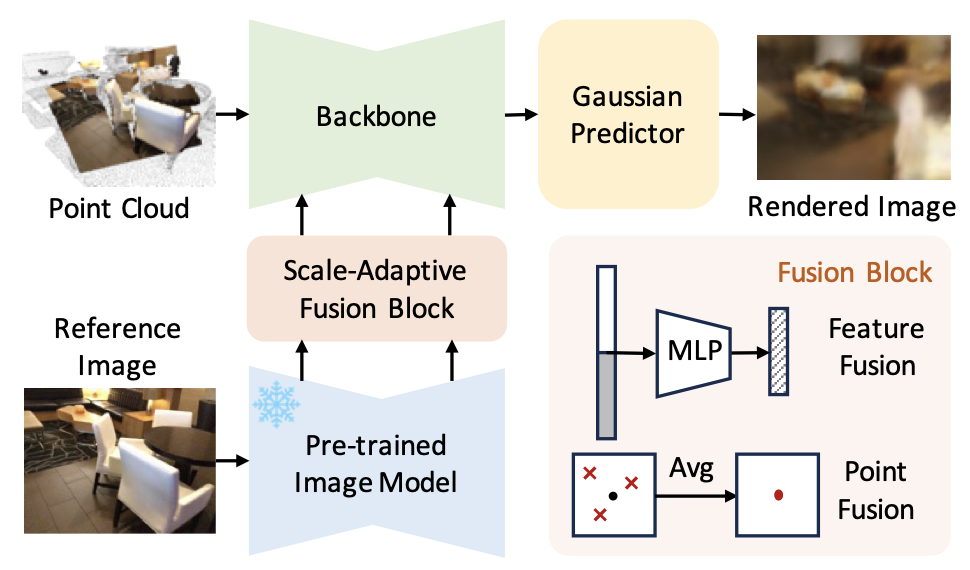
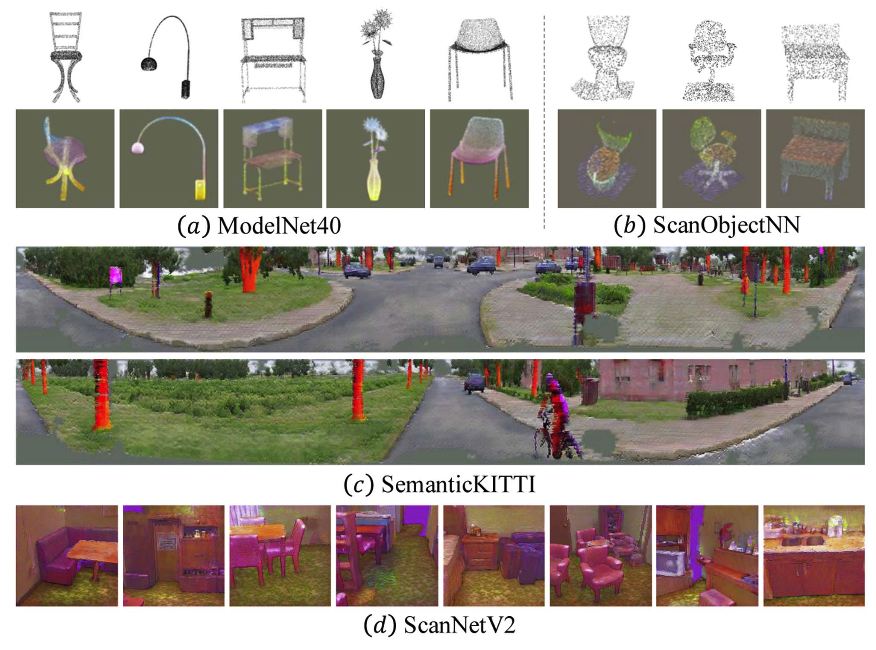
Ziyi Wang*, Yanran Zhang*, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Code] UniPre3D is a unified pre-training method that can be applied to both object-level and scene-level point clouds. It is supported by cross-modal Gaussian splatting technique. |
|
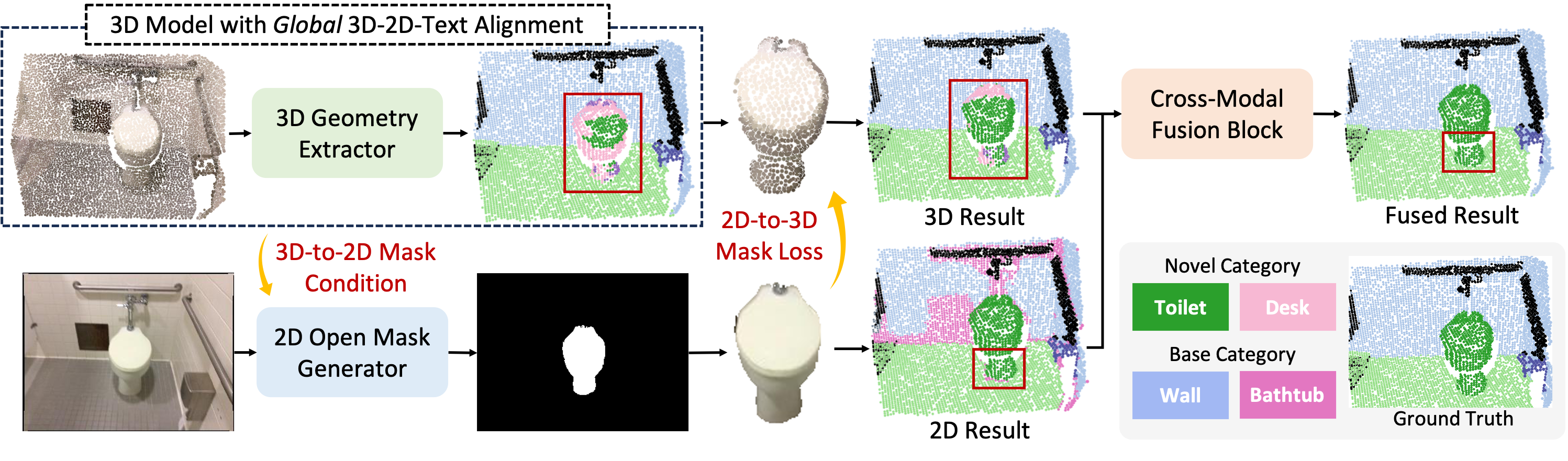
Ziyi Wang*, Yanbo Wang*, Xumin Yu, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] XMask3D is a framework that propose mask-level reasoning techniques to empower 3D segmentation model with open vocabulary capacity under the assistance of the pre-trained 2D mask generator. |
|
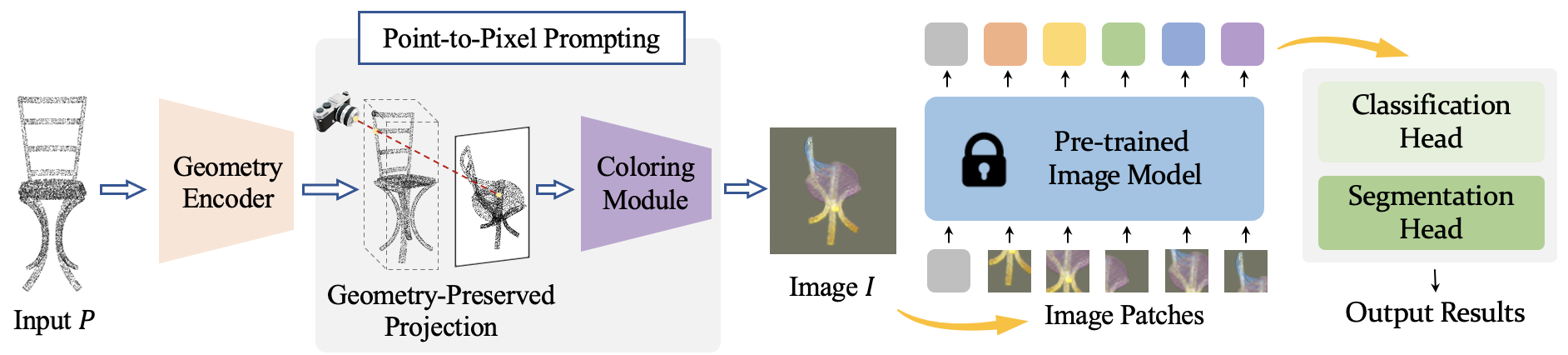
Ziyi Wang, Yongming Rao, Xumin Yu, Jie Zhou , Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 [IEEE] [Code] [Project Page] P2P++ is the extended journal version of P2P. We further propose Pixel-to-Point Distillation to make P2P applicable in scene-level perception tasks. |
|
Ziyi Wang*, Yi Wei*, Yongming Rao, Jie Zhou , Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023 [IEEE] [Code] [Project Page] DPV-RAFT is the extended journal version of PV-RAFT. We further propose Spatial Deformation and Temporal Deformation to enhance PV-RAFT. |
|
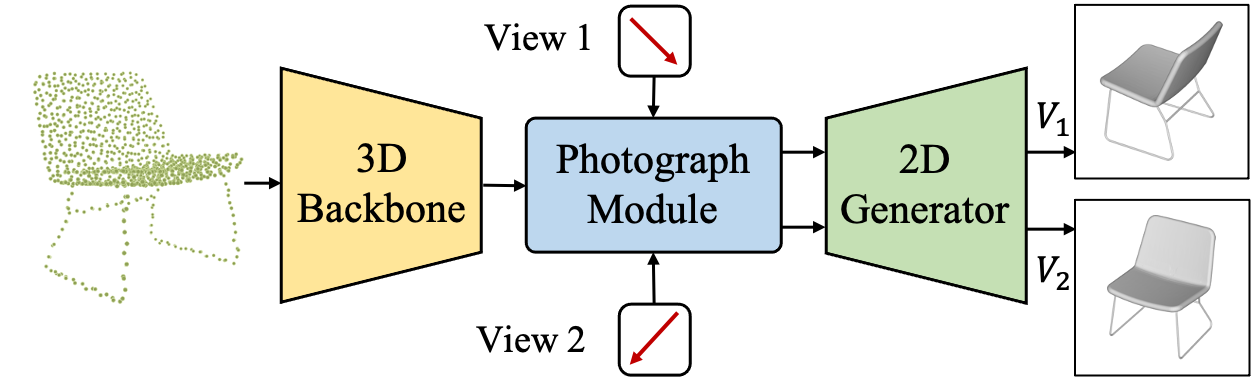
Ziyi Wang*, Xumin Yu*, Yongming Rao, Jie Zhou , Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [arXiv] [Code] [Project Page] TAP is a 3D-to-2D generative pre-training method that generate projected images of point clouds from instructed perspectives. |
|
Ziyi Wang*, Xumin Yu*, Yongming Rao*, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 Spotlight [arXiv] [Code] [Project Page] [中文解读] P2P is a framework to leverage large-scale pre-trained image models for 3D point cloud analysis. |
|
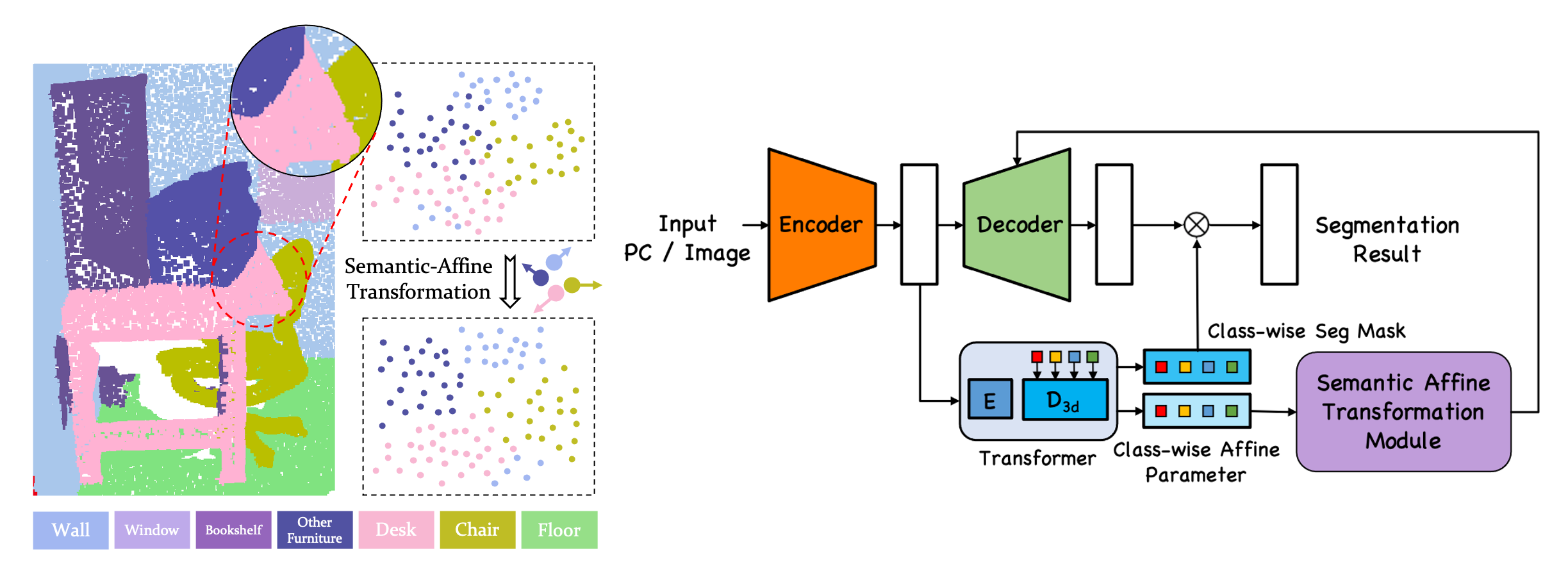
Ziyi Wang, Yongming Rao, Xumin Yu, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] We present Semantic-Affine Transformation that transforms decoder mid-level features of the encoder-decoder segmentation network with class-specific affine parameters. |

|
Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [中文解读] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |

|
Wenliang Zhao*, Yongming Rao*, Zyi Wang, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We present a deep interpretable metric learning (DIML) that adopts a structural matching strategy to explicitly aligns the spatial embeddings by computing an optimal matching flow between feature maps of the two images. |
|
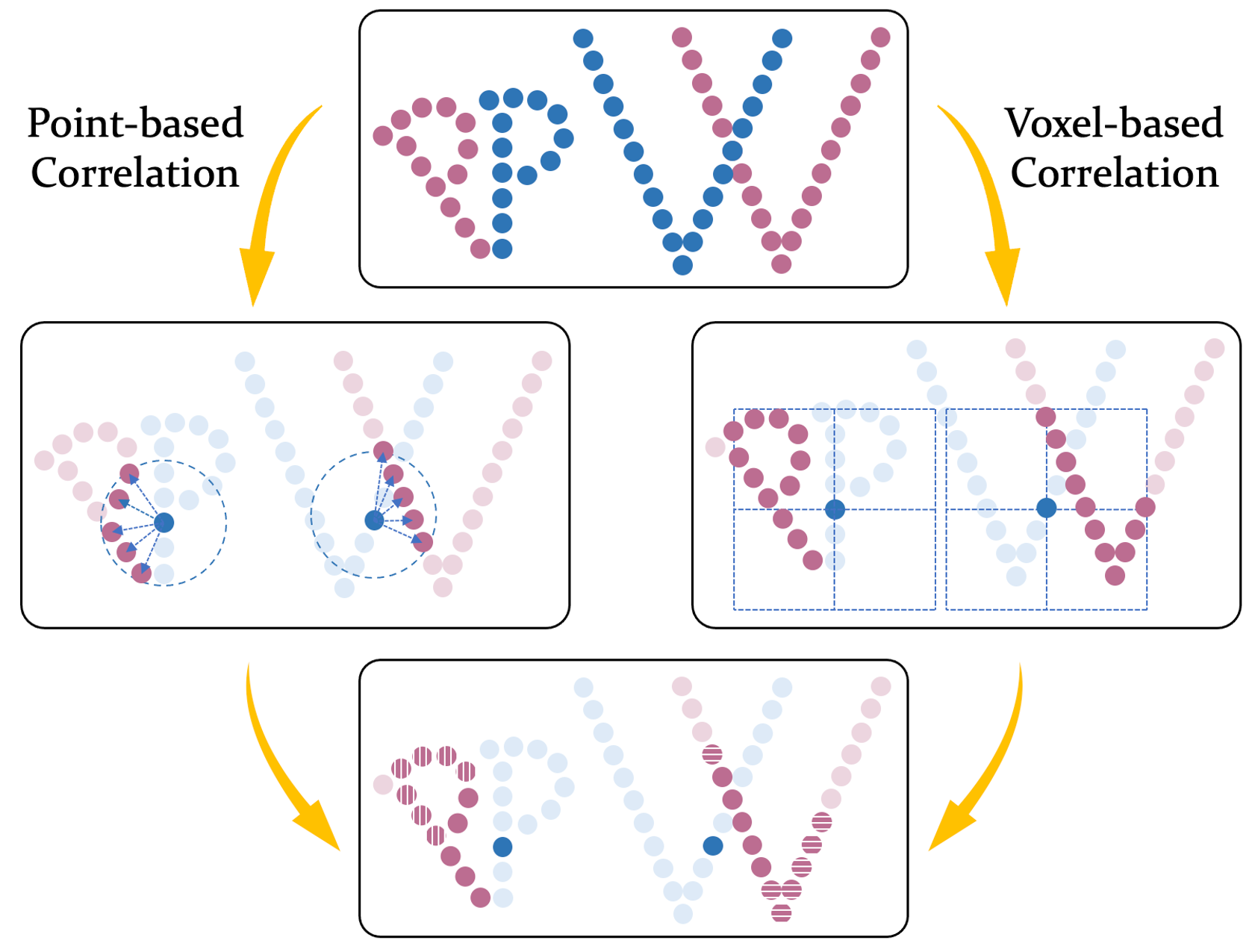
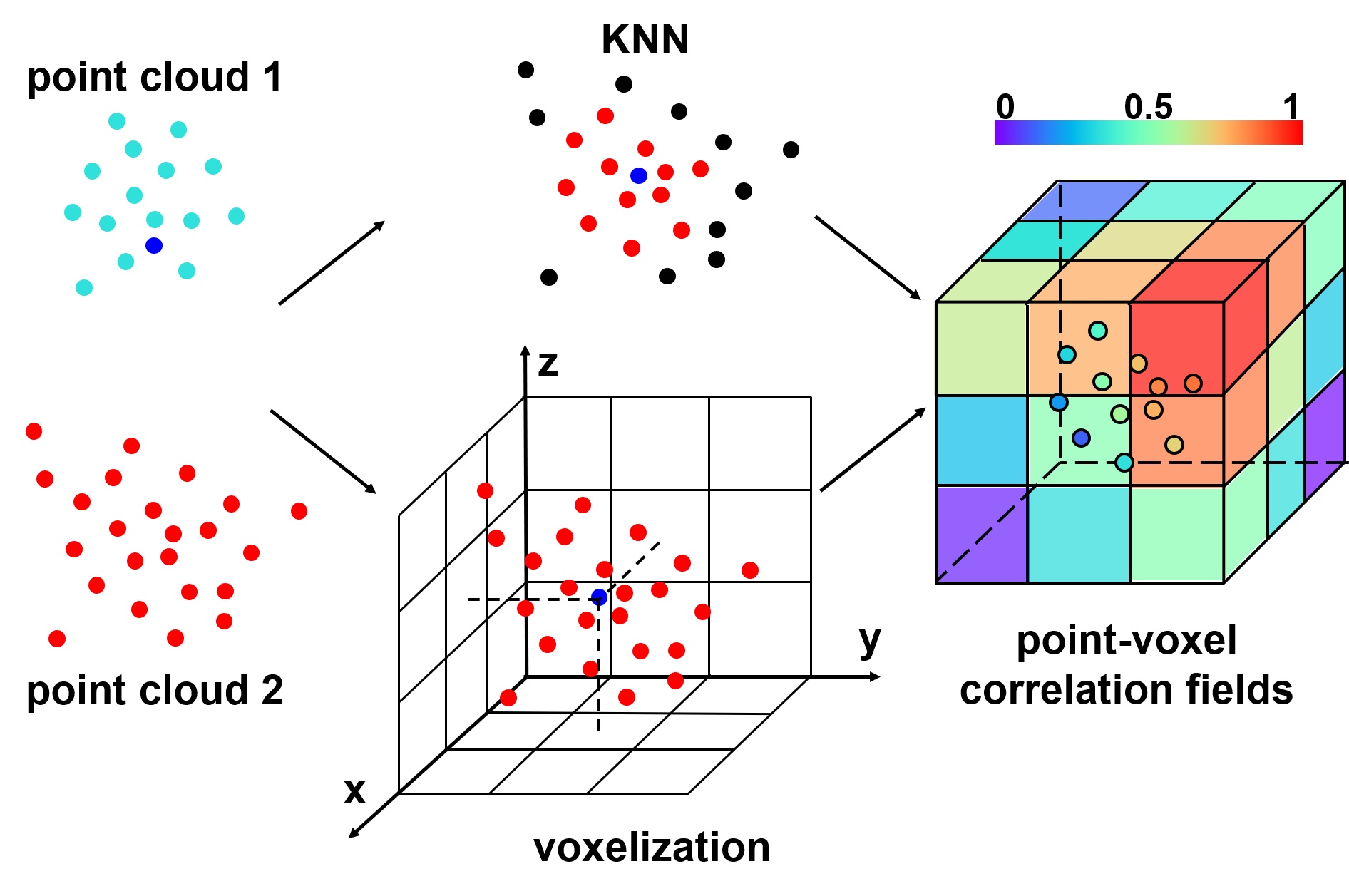
Yi Wei *, Ziyi Wang*, Yongming Rao*, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [arXiv] [Code] We present point-voxel correlation fields for 3D scene flow estimation which migrates the high performance of RAFT and provides a solution to build structured all-pairs correlation fields for unstructured point clouds. |
|
|
|
|
|
|
© Ziyi Wang | Last updated: July 16, 2026